Publications
\\\\* equal contribution; † corresponding author.
2026
-
CVPR FindingDirect Language Embedding Enables Gaussian Splatting for Large ScenesAccepted by CVPR Finding, 2026
-
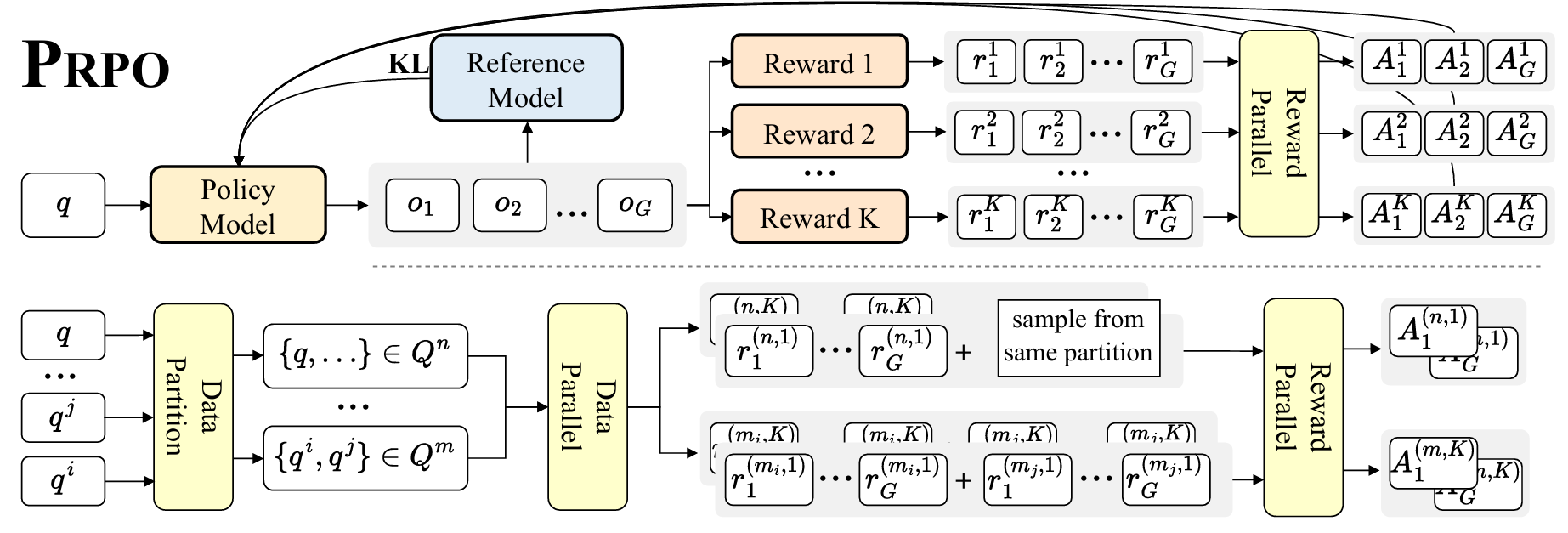 Chart Deep Research in LVLMs via Parallel Relative Policy OptimizationAccepted by ICLR, 2026
Chart Deep Research in LVLMs via Parallel Relative Policy OptimizationAccepted by ICLR, 2026




2025




















2024
-
TPAMI2024A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-oriented PerspectiveAccepted by TPAMI, 2024
-
CVPR2024Curriculum Point Prompting for Weakly-Supervised Referring Image SegmentationAccepted by CVPR, 2024
-







2023
-
ICCV2023
-
TPAMI2023A Unified Visual Information Preservation Framework for Self-supervised Pre-training in Medical Image AnalysisAccepted by TPAMI, 2023
-
WildRefer: 3D Object Localization in Large-scale Dynamic Scenes with Multi-modal Visual Data and Natural LanguagearXiv preprint arXiv:2304.05645, 2023


2022
2021
-
TMM2021Structured attention network for referring image segmentationAccepted by Transactions on Multimedia, 2021
-
CVPR2021
-
ICCV2021Convnets vs. transformers: Whose visual representations are more transferable?Accepted by ICCV, 2021
2020
-
TPAMI2020
-
ECCV2020